只用一行代码可以提高模型表现吗?
只用一行代码能提高模型表现吗?
一行代码能做什么,有的人能发顶会,而有的人…
相信大家在训练模型的时候都会遇到一个现象,训练集损失降到一定的值之后,验证集的损失就开始上升了,在实验中一般奇怪的是准确率还跟着上升。这是为什么?如下图所示:
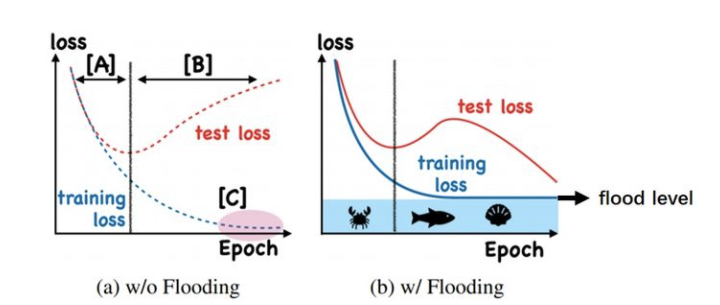
先看图(a),是一个正常的训练过程,对于阶段A,随着training loss的降低,test loss也会 跟着降低;
但是到阶段B后,我们继续在训练集上训练,会让test loss上升。我们通常认为这是过拟合了,因为泛化误差变大了。
图 (b) 是ICML2020上《Do We Need Zero Training Loss After Achieving Zero Training Error》提出的flooding方法。这是一种使训练损失在一个小常量附近浮动的方法,以防止训练损失趋近于零 (这也是flooding的约束假设)。
为什么要防止训练损失趋近于0呢?
如果我们在模型已经记住了训练数据,完全没有错误的情况下仍继续训练,训练损失可以很容易地变得(接近)零,特别是对于过度参数化的模型。我们的模型其实就是个函数拟合器,在训练集上拟合的太好就容易发生过拟合。
经过推导(下文),flooding其实也和正则化的一些方法一样,通过各种方式避免训练过多。正则化方法可以被认为是间接控制训练损失的方法,通过引入额外的约束假设。
这里科普一下花书对于正则化的官方定义:
凡是可以减少泛化误差(过拟合) 而不是减少训练误差的方法——正则化方法。
其实对抗训练从理论上也是一种正则化方法,而正则化其实也可以理解成我们在求解最优化问题中的约束条件。我们通常希望将模型约束到一个较为”平坦“的损失,能够使得模型鲁棒性、泛化性更好。
从svm的角度来思考这个问题。对于一个线性可分的二分类问题,有无数条分类面能将其分开,而svm是去挑选能满足“最大间隔”的分类器。从另一个角度来理解是,越平坦的损失,是不是能越尽可能的将不同类给分开,因为样本进行些许扰动,损失的变化不会太大,相当于进行细微扰动后的样本也不会被分类到另一类去。
flooding 方法分析
论文其实就一行代码:
1 | logits = model(x) |
泛洪是直接解决训练损失变为(接近)零的问题。当训练损失达到合理的小值时,泛洪故意阻止训练损失的进一步减少。
设原来的损失函数为 $\mathcal{L}(\theta)$ ,改为 $\tilde{\mathcal{L}}(\theta)$:
其中 b 是超参数阈值
当 $\mathcal{L}(\theta) > b$ 时, $ \tilde{\mathcal{L}}(\theta) =\mathcal{L}(\theta)$, 这个时候和正常他梯度下降无异;
当$\mathcal{L}(\theta) <b$ 时, $ \tilde{\mathcal{L}}= 2b - \mathcal{L}(\theta)$ 变成了梯度上升了。
当training loss大于一个阈值(flood level)时,进行正常的梯度下降;当training loss低于阈值时,会反过来进行梯度上升,让training loss保持在一个阈值附近,让模型持续进行“random walk”,并期望模型能被优化到一个平坦的损失区域,这样发现test loss进行了double decent!一个简单的理解是,这和early stop类的方法类似,防止参数被优化到一个不好的极小值出不来。
这里借用 我们真的需要把训练集的损失降低到零吗? 的推导
当损失函数达到 b 之后,训练流程大概就是在交替执行梯度下降和梯度上升。直观想的话,感觉一步上升一步下降,似乎刚好抵消了。事实真的如此吗?我们来算一下看看。假设先下降一步后上升一步,学习率为 $\epsilon$,那么:
其中 $g(\theta) = \nabla_{\theta} \mathcal{L}(\theta)$ , 现在有:
近似那一步是使用了泰勒展式对损失函数进行近似展开,最终的结果就是相当于损失函数为梯度惩罚 $\Vert g(\theta)\Vert^2=\Vert\nabla{\theta}\mathcal{L}(\theta)\Vert^2$、学习率为 $\frac{\varepsilon^2}{2}$ 的梯度下降。更妙的是,改为“先上升再下降”,其表达式依然是一样的(这不禁让我想起“先升价10%再降价10%”和“先降价10%再升价10%”的故事)。因此,平均而言,Flooding对损失函数的改动,相当于在保证了损失函数足够小之后去最小化 $\Vert\nabla{\theta}\mathcal{L}(\theta)\Vert^2$,也就是推动参数往更平稳的区域走,这通常能提供提高泛化性能(更好地抵抗扰动),因此一定程度上就能解释Flooding其作用的原因了。
本质上来讲,这跟往参数里边加入随机扰动、对抗训练等也没什么差别,只不过这里是保证了损失足够小后再加扰动。读者可以参考《泛化性乱弹:从随机噪声、梯度惩罚到虚拟对抗训练》了解相关内容,也可以参考“圣经”《深度学习》第二部分第七章的“正则化”一节。
关于 b 的选择
b 的选择,原论文说 b 的选择是一个暴力迭代的过程,需要多次尝试
The flood level is chosen from $b\in {0, 0.01,0.02,…,0.50}$
脑洞:b 无非就是决定什么时候开始交替训练罢了,那如果我们从一开始就用不同的学习率进行交替训练呢?也就是自始自终都执行
其中 $\varepsilon_1> \varepsilon_2$,这样我们就把 b 去掉了(引入了 $ \varepsilon_1, \varepsilon_2$ 的选择,天下没有免费的午餐)。重复上述近似展开,我们就得到
这就相当于自始自终都在用学习率 $\varepsilon1-\varepsilon_2$ 来优化损失函数 $\mathcal {L}(\theta) + \frac {\varepsilon_1\varepsilon_2}{2 (\varepsilon_1 - \varepsilon_2)}\Vert\nabla{\theta}\mathcal {L}(\theta)\Vert^2$ 也就是说一开始就把梯度惩罚给加了进去,这样能提升模型的泛化性能吗?《Backstitch: Counteracting Finite-sample Bias via Negative Steps》里边指出这种做法在语音识别上是有效的,请读者自行测试甄别。
这种做法在这篇博客上做了尝试,可能验证loss会降的更低一点,但具体得分情况还得自己尝试。我们真的需要把训练集的损失降到零吗?
实验测试
在第五届达观杯竞赛中使用的BERT模型,进行了实验。原论文的实验配合Eearly Stop 和 Weight decay 一起使用效果较好。重要的要花时间去调的是b的取值,初始的b值一般设为 验证集loss开始上扬的值的一半。
在我的实验中发现,在预训练后的bert模型加上dice loss之后,验证集loss上扬的情况就不存在了。但是预训练后的bert加上cross entropy还是会上扬。而未经过预训练的bert无论是在dice loss还是cross entropy上都会上扬。分析背后的原因可能有二:
- 预训练后的bert模型表现更加稳定,对数据有一定的认识。
- cross entropy对每个样本都一视同仁,不管当前样本是简单还是复杂。当简单样本有很多时,模型训练就会被这些简单的样本占据,使得模型难以从复杂样本中学习,而dice loss一旦模型正确分类当前样本(刚刚过0.5),就会使模型更少关注它,而不是像交叉熵那样,鼓励模型迫近0或1这两个点。这就能有效避免模型训练受到简单样本的支配,同时也防止了过拟合。
无flooding的情况下
预训练后的bert+dice loss 的情况如下图所示。

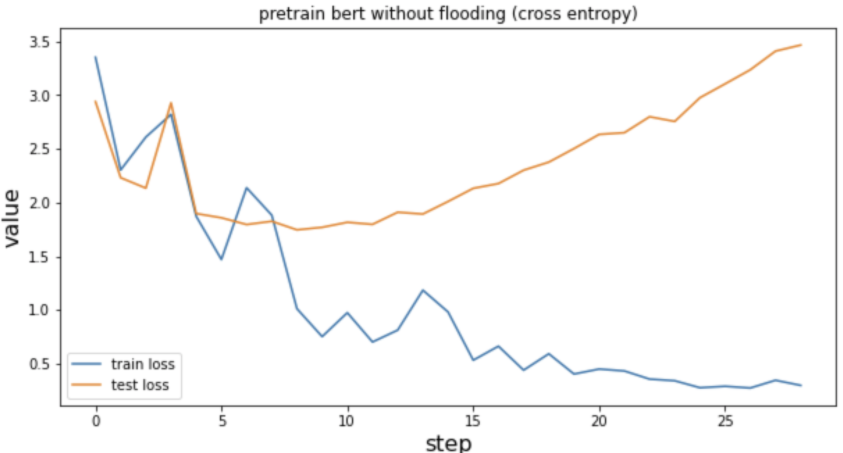
预训练后的bert + cross entropy,依旧上扬但相比下一个图未经预训练bert的情况要好一些。
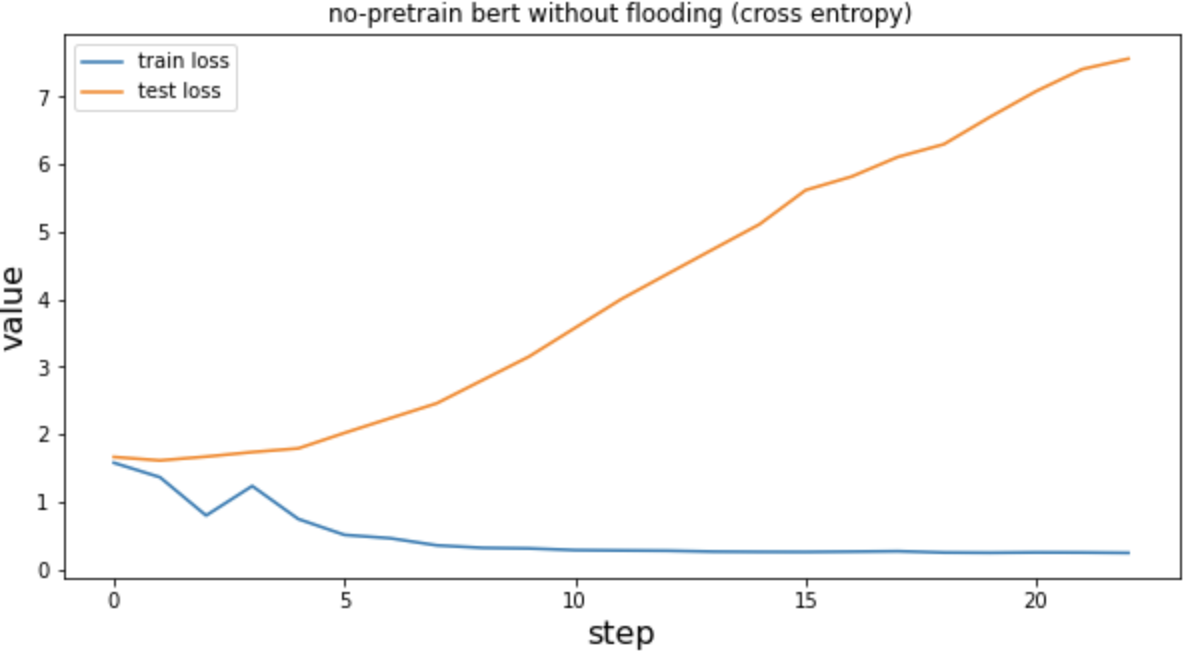
未经预训练的bert+cross entropy
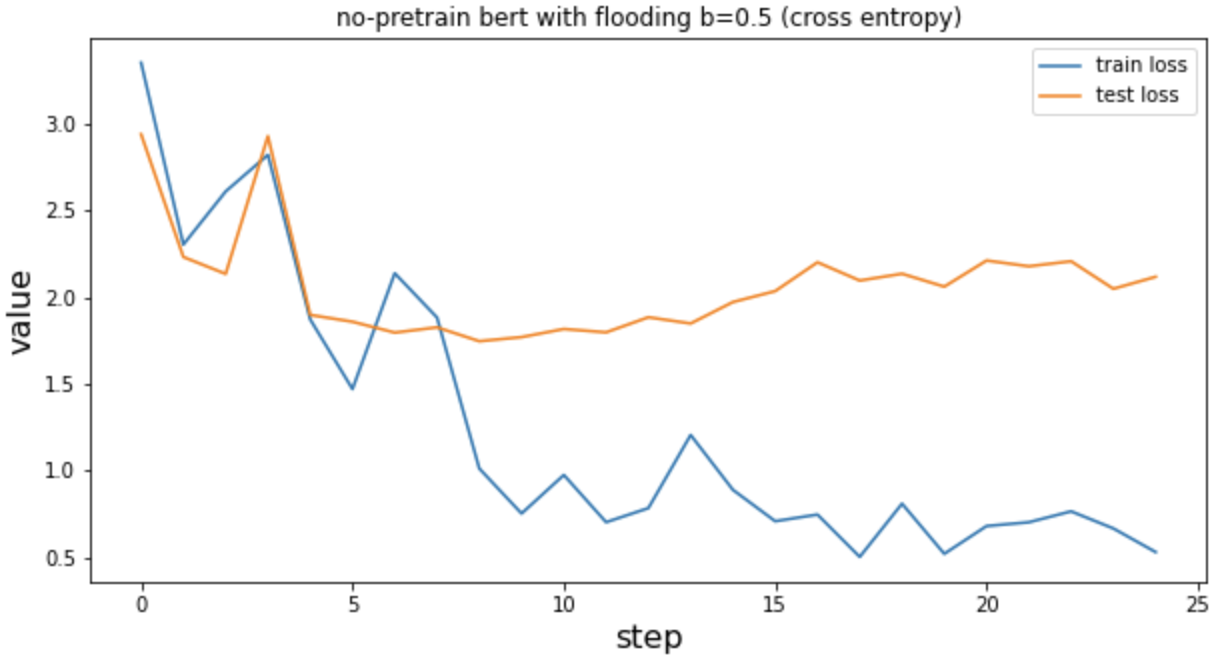
经过flooding后
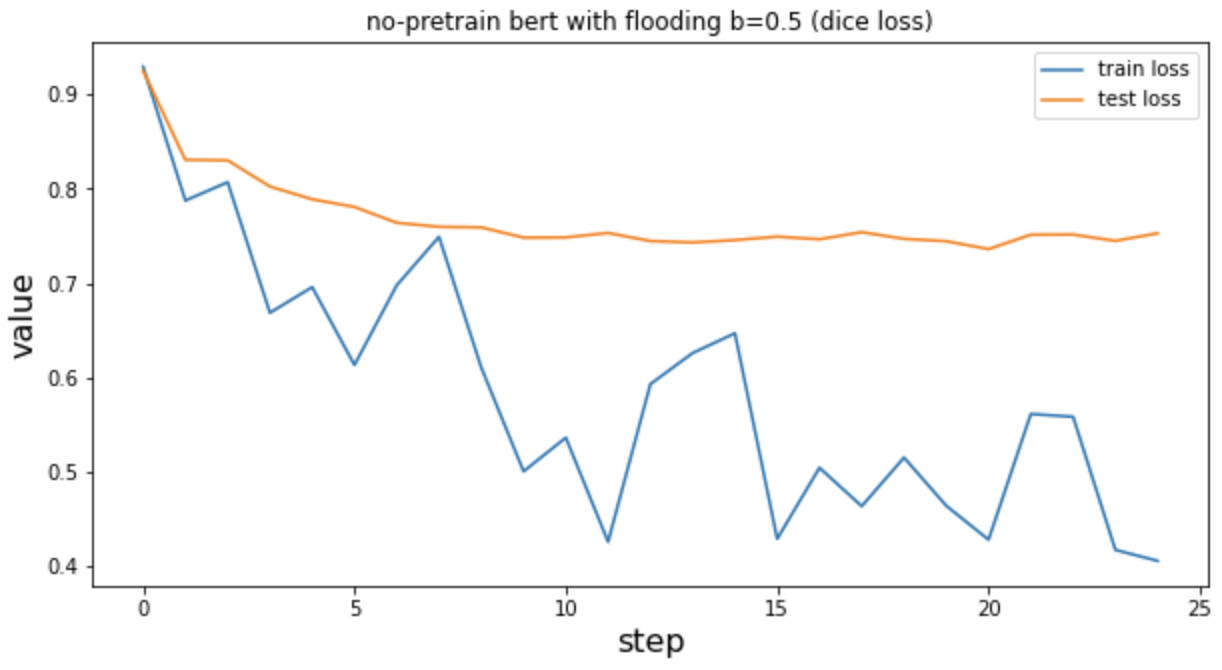
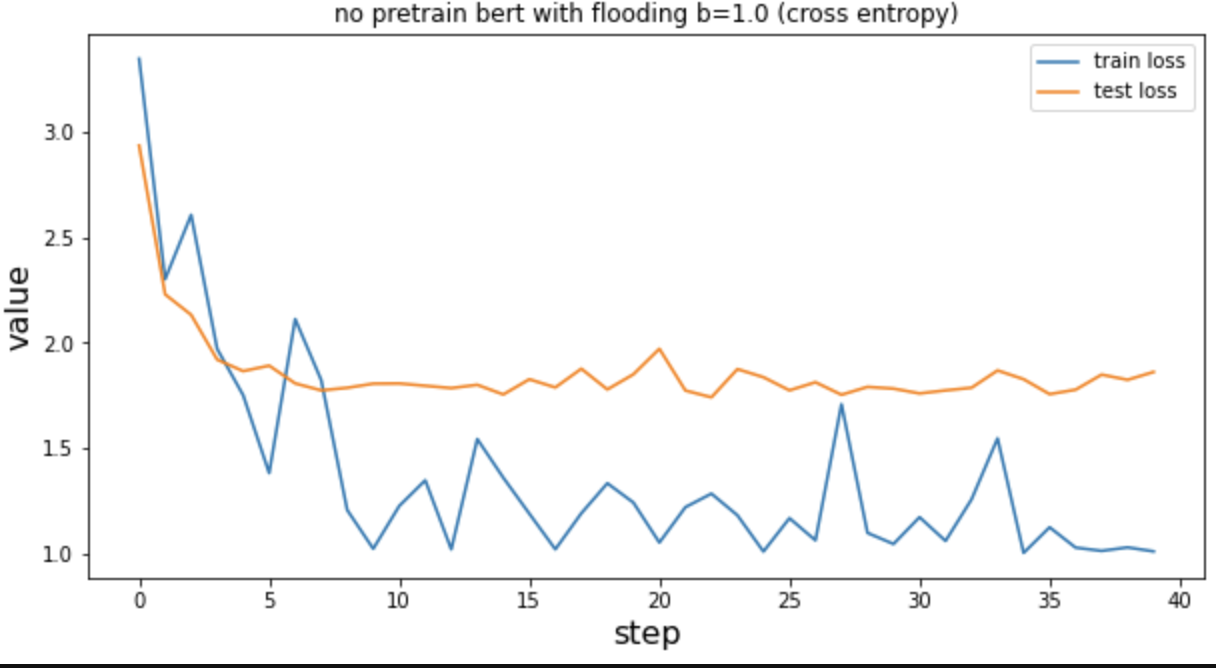
No_pretrain bert/ cross entropy/ flooding b=0.5/ weight decy=0.01/ early patience=12 相比于上图验证集的loss已经不在无止境的上扬了。在下图的15到20step之间train的loss也不是和上图一样一路走低,而是出现了波动,这和论文的预期一致。
未经预训练后的bert b=0.5 dice loss
未经预训练后的bert,b=1.0 ,cross entropy
结论
flooding确实可以缓解验证集损失上扬的现象,而且本质还是个正则化的功能。至于具体效果有多大,是好是坏还是要根据具体任务去调试b的取值。
不过我的实验可以证明 预训练后的bert 和 dice loss 确实是可以让模型避免出现类似过拟合的现象。
References
 wechat
wechat alipay
alipay


