RealFormer: Transformer Likes Residual Attention
RealFormer: Transformer Likes Residual Attention
提出了一个简单的基于Transformer的体系结构,创建一条“直接”路径在整个网络中传播原始注意力分数
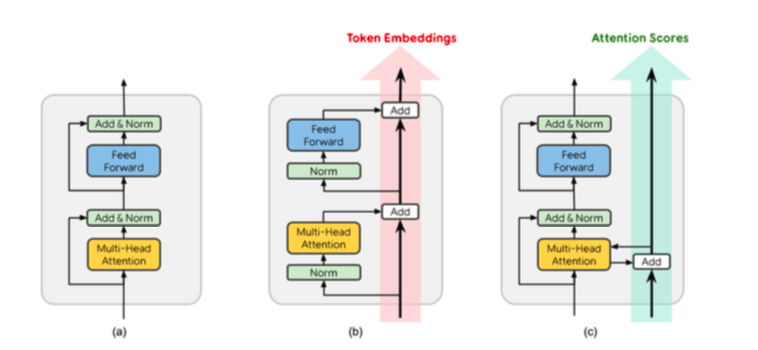
如下图(c), 每个RealFormer层都获取前一层中所有注意力头部的原始注意力分数,并在顶部添加“残差分数”(计算方式与常规Transformers中的注意力分数相同)。
换句话说,RealFormer可以被视为向Post-LN Transformer添加一个简单的跳跃连接。不会向计算图中添加任何乘法运算,因此预期性能与之相当。
RealFormer中的AT往往更稀疏,跨层相关性更强,我们认为这可能具有一些正则化效应,可以稳定训练,有利于微调。
 t
t
- (a) 传统transformer的PostLN
- (b) PreLN 论文:ON LAYER NORMALIZATION IN THE TRANSFORMER ARCHITECTURE,这种设计为每个子层增加了LN作为“预处理”步骤。
方法
标准Transformer Encoder
Post-LN是Vaswani等人提出的原创体系结构。对每个子层末尾的输出进行标准化。
相反,Pre-LN规格化子层输入,并创建直接路径(没有LN)来传播序列中的令牌嵌入。
Residual Attention Layer Transformer
RealFormer紧跟Post-LN设计,简单地增加了一个skip edge来连接相邻层中的多头注意力,如上图c所示。
形式上添加一个$Prev$,是上一个softmax的注意力分数也就是pre-softmax,形状为$(heads,\text{from_seq_len},\text{to_seq_len})^2$
$Prev_i$ 的形状为$(\text{from_seq_len,to_seq_len})$ 对应于每个$head_i$
新的注意力分数$\frac{Q’K’^T}{\sqrt{d_k}}+Prev’$
实验
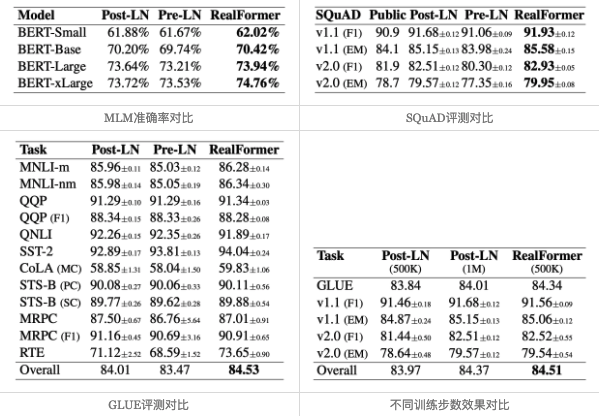
值得特别指出的是第一张图和第四张图。从第一张图我们可以看到,对于RealFormer结构,加大模型规模(large到xlarge)可以带来性能的明显提升,而ALBERT论文曾经提到加大BERT的模型规模并不能带来明显受益,结合两者说明这可能是PostLN的毛病而不是BERT的固有毛病,换成RealFormer可以改善这一点。从第四张图我们可以看到,RealFormer结构训练50万步,效果就相当于PostLN训练100万步,这表明RealFormer有着很高的训练效率。
除了上述实验外,论文还对比了不同学习率、不同Dropout比例的效果,表明RealFormer确实对这些参数是比较鲁棒的。原论文还分析了RealFormer的Attention值分布,表明RealFormer的Attention结果更加合理。
分析
RealFormer对梯度下降更加友好,这不难理解,因为$An = \frac{Q_nK_n^T}{\sqrt{d_k}} + A{n-1}$的设计确实提供了一条直通路,使得第一层的Attention能够直通最后一层,自然就没有什么梯度消失的风险了。相比之下,PostLN是 $LayerNorm(x+f(x))$ 的结构,看上去$x+f(x)$防止了梯度消失,但是LayerNorm这一步会重新增加了梯度消失的风险,造成的后果是初始阶段前面的层梯度很小,后面的层梯度很大,如果用大学习率,后面的层容易崩,如果用小学习率,前面的层学不好,因此PostLN更难训练,需要小的学习率加warmup慢慢训。
还有一个就是叠加的问题PreLN每一步都是$x+f(x)$的形式,到了最后一层变成了$x+f_1(x)+f_2(x)+…++f_n(x)$的形式,一层层累加,可能导致数值和方差都很大,最后迫不得已强制加一层Layer Norm让输出稳定下来。这样,尽管PreLN改善了梯度状况,但它本身设计上就存在一些不稳定因素。
Realformer的$An = \frac{Q_nK_n^T}{\sqrt{d_k}} + A{n-1}$存在叠加问题吗?如果只看A,那么确实有这样的问题,但A后面还要做个softmax归一化后才参与运行,也就是说,模型对矩阵A是自带归一化功能的,所以它不会有数值发散的风险。而且刚刚相反,随着层数的增加,A的叠加会使得A的元素绝对值可能越来越大,Attention趋近于onehot形式,造成后面的层梯度消失,但是别忘了,我们刚才说PostLN前面的层梯度小后面的大,而现在也进一步缩小了后面层的梯度,反而使得两者更同步,从而更好优化了;
另一方面Attention的概率值可能会有趋同的趋势,也就是说Attention的模式可能越来越稳定了。带来类似ALBERT参数共享的正则化效应,这对模型效果来说可能是有利的。同时,直觉上来想,用RealFormer结构去做FastBert之类的自适应层数的改进,效果会更好,因为RealFormer的Attention本身会有趋同趋势,更加符合FastBert设计的出发点。
此外,我们也可以将RealFormer理解为还是使用了常规的残差结构,但是残差结构只用在Q,K而没有用在V上。
为啥V“不值得”一个残差呢?从近来的一些相对位置编码的改进中,笔者发现似乎有一个共同的趋势,那就是去掉了V的偏置,比如像NEZHA的相对位置编码,是同时在Attention矩阵(即Q,K)和V上施加的,而较新的XLNET和T5的相对位置编码则只施加在Attention矩阵上,所以,似乎去掉V的不必要的偏置是一个比较好的选择,而RealFormer再次体现了这一点。
RealFormer与Baseline Transformers在本质上有什么不同?
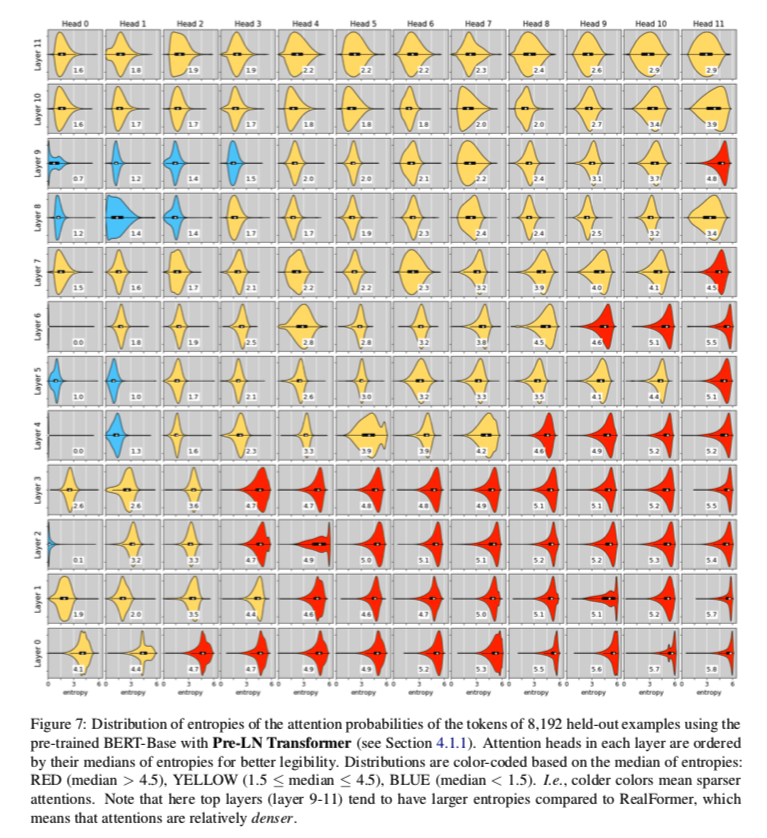
dev set中随机抽样了8,192个示例,并可视化了这些示例中每个token(不包括padding)在表2中的三个预先训练的BERT-Base模型中的所有层和所有头部的注意概率分布。
特别地,对于每个(token、layer、head)三元组,我们计算关注权重(概率)的熵作为关注度的“稀疏度量”。直观地说,熵越低,注意力权重分布就越偏斜,因此注意力就越稀疏。
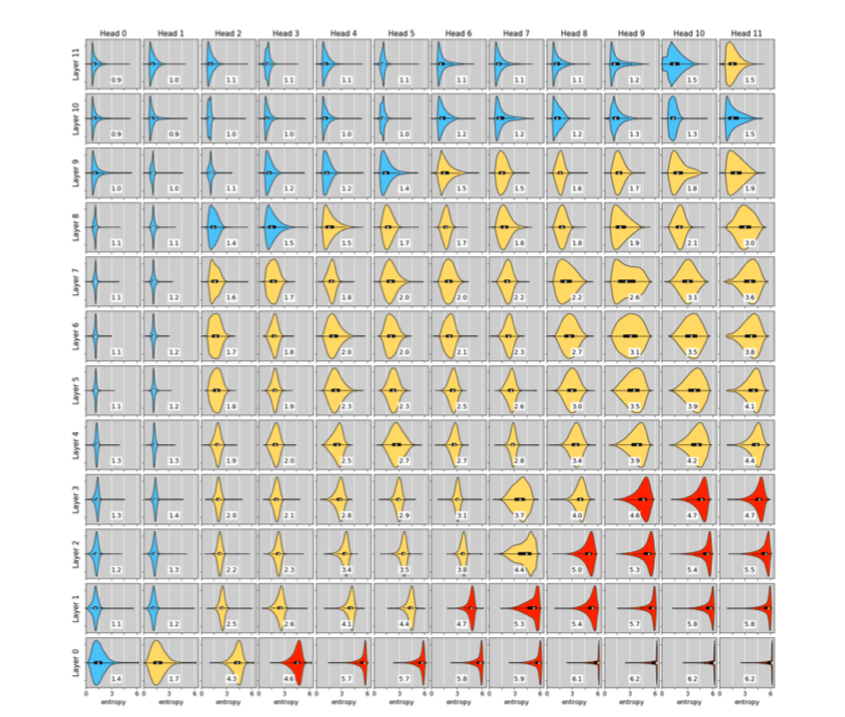
用RealFormer训练好的BERT-BASE对8192个突出例子的标记注意概率的熵分布
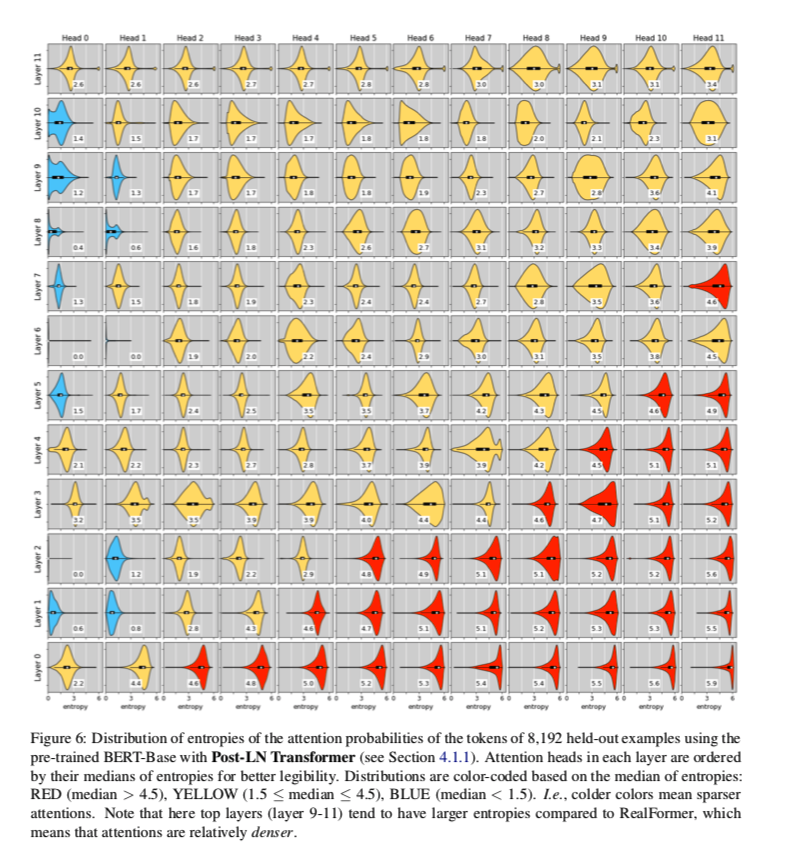
为了更好地辨认,每一层中的注意力都是按照熵的中位数排序的。根据熵的中位数对分布重新进行颜色编码:红色(中位数>4.5)、黄色(1.5≤中位数≤4.5)、蓝色(中位数<1.5)。也就是说,颜色越冷意味着注意力越稀疏。有一个明显的趋势是,较高的层往往具有较稀疏的注意力。
下面的是post-LN和pre-LN的熵分布
 wechat
wechat alipay
alipay