Graph Transformer for Graph-to-Sequence Learning
Graph Transformer for Graph-to-Sequence Learning
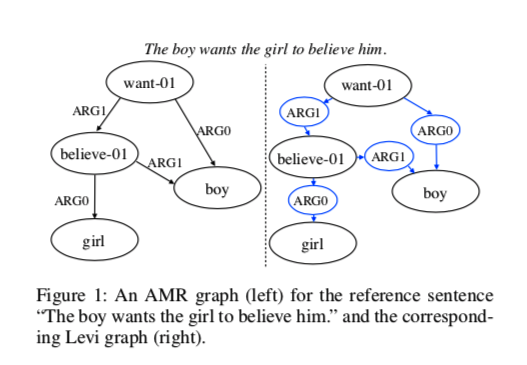
这篇论文应用于在基于抽象语义表示(AMR)的文本生成和基于句法的神经机器翻译,句法机器翻译并入源端语法信息可以提高翻译质量。如图给出了AMR到文本生成的示例。
论文应用Graph Transformer,其与限制近邻之间信息交换的图神经网络不同,Graph Transformer使用显式关系编码,允许两个远距离节点之间的直接通信。它为全局图结构建模提供了一种更有效的方法。
这篇论文想解决的是打破传统GNN的局部邻接特性,使用高效的全局信息。
Methed
对于n个节点的图,以前的图神经网络将节点表示$v_i$计算为输入节点 $i$ 及其所有一阶邻域 $N(i)$的函数。图结构由每个节点表示的感受野隐式反映。然而,这种本地通信设计对于远程信息交换可能是低效的。
所以引入Graph Transformer,它提供了一种截然不同的范例,可以实现关系感知的全球通信。
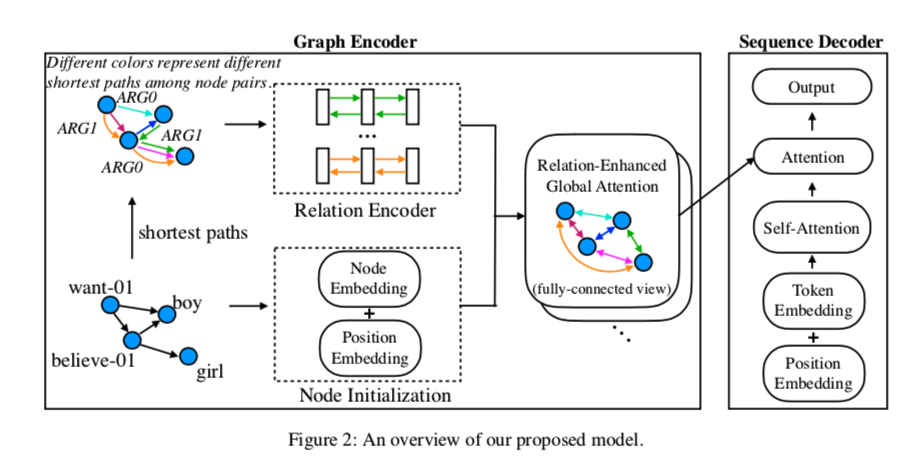
作者提出的是关系增强的全局注意力机制,和Graphromer一样任何节点对之间的关系被描述为它们之间的最短关系路径。
Graph Encoder
责将输入图形转换为一组相应的节点嵌入。核心问题是如何在允许全连通通信的同时保持图的拓扑结构。
作者的想法是将两个节点之间的显式关系表示融入到它们的表示学习中。在标准的多头注意中,元素 $x_i$ 和元素 $x_j$之间的注意分数简单地分别是它们的查询向量和键向量的点积:
假设我们已经学习了节点i和节点j之间的关系 $r_{ij}$ 的矢量表示,我们将其称为关系编码。
$r{i\to j};r{j\to i}$ 为正向和反向关系编码。
如果把正反两个关系编码加到节点embedding中,注意力分数计算可以为:
直观上,等式项意义:
- (a) 捕获纯粹基于内容的content-based addressing,,这是普通注意力机制中的原始term。
- (b) 依赖于源节点的关系偏置。
- (c) 依赖于目标节点的关系偏置。
- (d) 对通用的关系偏差进行编码。
在这里作者使用的是节点间的最短路径来表示关系。
Relation Encoder
从概念上讲,关系编码为模型提供了关于应该如何收集和分发信息的全局指导,即在哪里关注。
对于NLP中的大多数图形结构,边标签传达了相邻节点之间的直接关系(例如,概念到概念所扮演的语义角色,以及两个单词之间的依存关系)。
作者将这种单跳关系定义扩展到多跳关系推理中,以刻画任意两个节点之间的关系。
例如第一个图中 want-01 到 girl的最短路径概念为,$\text{want-01} \to^{ARG1} \text{believe-01}\to^{ARG0} girl$ 传达girl是wanted的目标。
直观地说,两个节点之间的最短路径给出了它们之间最密切且可以说是最重要的关系
作者使用GRU将关系序列转换为分布表示。$i$ 到 $j$ 的最短路径关系为: $sp_{i\to j}= [e(i,k_1), e(k1,k2),…,e(k_n,j)]$
其中$e(,)$是边标签,$k_{1:n}$ 是中继节点。
concat最终关系表达为$r_{ij} = [\overrightarrow s_n; \overleftarrow s_0]$
Bidirectionality
因为应用任务常是DAG,作者给做成理论双向交互的。反转边连接与原始边相同的两个节点,但方向不同,并使用反转标签。
此外作者还在每个图中引入一个额外的全局节点和自环边,该节点具有特殊标签GLOBAL与其他所有节点都有一条直接边。全局节点的最终表示$x_{global}$用作整个图表示。
Absolute Position
除了成对关系之外,一些绝对位置信息也是有益的。例如,AMR图的根作为整体焦点的粗略表示,使得到根节点的最小距离部分地反映了相应概念在整句语义中的重要性。
位置嵌入添加到编码器堆栈底部的输入embedding中。例如,第一个中的Want-01是AMR图的根节点,因此其索引应该为0。也将全局节点的索引表示为0。
Sequence Decoder
和普通Transformer Decoder没什么大的区别
特殊的一点,使用全局图形表示$x_{global}$来初始化每个时间步的隐藏状态。
然后,通过在编码器的输出上交错多轮关注来更新每个时间步骤t处的隐藏状态 $h_t$
 wechat
wechat alipay
alipay





