A Generalization of Transformer Networks to Graphs
A Generalization of Transformer Networks to Graphs
作者提出了一种适用于任意图的Transformer结构的。
针对问题:
最初的Transformer相当于一个在所有单词之间都有连接的全连通图上操作,但这样的体系结构没有利用图的连通感应偏差,并且当图拓扑结构重要时,没有被编码到节点特征汇总,性能不好。
解决方案
作者提出四个新特性:
- 首先,注意机制是图中每个节点的邻域连通性的函数。
- 其次,位置编码由Laplacian特征向量来表示,用在了原始Transformer在NLP中常用的正弦位置编码。
- 第三,用batch normalization层代替layer normalization,提供了更快的训练速度和更好的泛化性能。
- 最后,将对任务至关重要的边缘特征表示,加入到该graph-transformer结构中。
相关工作
Graph Transformer-2019
首先作者提出在2019年Graph Transformer那篇文章,为了捕捉全局信息将attention应用在全图节点上替代了局部邻居。
但作者认为这样限制了稀疏性的有效利用,这是在图数据上学习比较重要的ductive bias。 为了获取全局信息的目的,作者认为还有其他方法可以合并相同的信息,而不是放弃稀疏性和局部上下文。
例如,使用特定于图形的位置特征(Zhang et al.2020),或节点拉普拉斯位置特征向量(Belkin和Niyoi 2003;Dwivedi等人)。2020)或相对可学习的位置信息(You、Ying和Leskovec 2019)、虚拟节点 (Li et al. 2015)等。
Graph-BERT-2020
其次作者在相关工作中评价了Graph-Bert那篇文章,其强调预先训练和并行化学习,使用一种子图批处理方案,创建固定大小的无链接子图,将其传递给模型,而不是原始图。
Graph-BERT采用几种位置编码方案的组合来捕获绝对节点结构和相对节点位置信息。由于原始图不直接用于Graph-BERT,并且子图在节点之间没有边(即,无链接),所提出的位置编码的组合试图在节点中保留原始图的结构信息。
HGT-2020、GTN-2019
Graph Transformer Networks(GTN)学习异构图,目标是将给定的异构图转换为基于元路径的图,然后执行卷积。
他们使用attention背后的重点是为了预置生成的meta-paths,除了能够处理任意数目的节点和边类型外,HGT还以基于中心节点和消息传递节点的时间戳差异的相对时间位置编码的形式捕获了异质图中信息流的动态变化。
本文贡献
提出稀疏性和位置编码是图变形器开发中的两个关键方面。与为特定的图形任务设计一个性能最佳的模型相反,这篇的工作是尝试一个通用的graph-Transformer模型。
- 提出了一种将Transformer网络可以用于任意结构同质图的方法,即Graph Transformer,并提出了一种具有边特征的扩展Graph Transformer,它允许使用显式的域信息作为边特征。
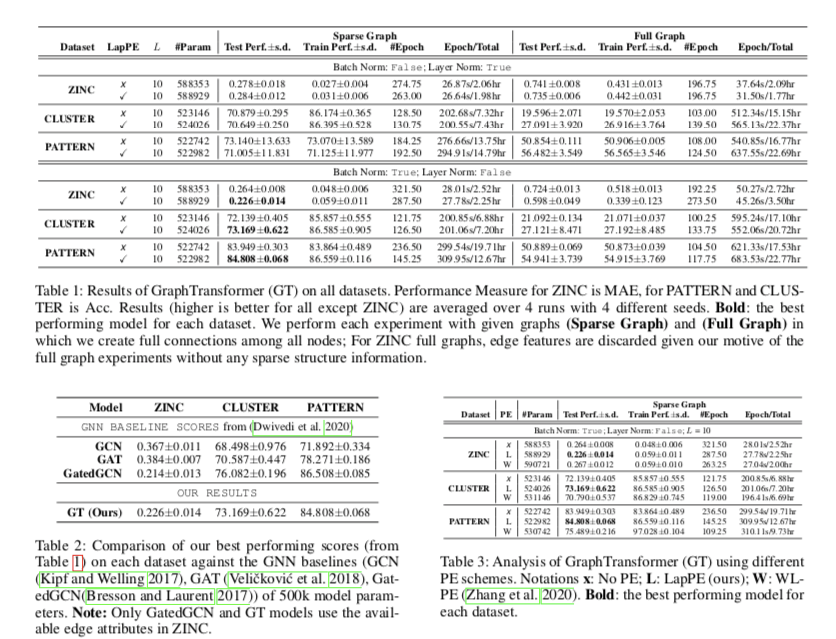
- 利用图数据集的拉普拉斯特征向量来融合节点位置特征, 与文献的比较表明,对于任意同质图,拉普拉斯特征向量比任何现有的编码节点位置信息的方法都要好。
- 实验证明其好于传统GNN
方法
图的稀疏性
在NLP Transformer中,句子被视为完全连通的图形,这种选择有两个原因:
- 很难在句子中的单词之间找到有意义的稀疏交互或联系。例如,句子中的一个词对另一个词的依赖性可以随上下文、用户的视角和特定应用而变化。一个句子中的词之间可能存在许多似是而非的基本事实连接,因此,句子的文本数据集没有显式的词交互可用。因此,让一个句子中的每个单词相互关注其他单词是有意义的,就像Transformer架构所遵循的那样。
- 在NLP Transformer中考虑的所谓的图通常具有少于数十或数百个节点。这在计算上是可行的,大型变压器模型可以在这种完全连通的文字图上进行训练。
在高达数百万或数十亿的节点大小。可用的结构为我们提供了丰富的信息源,可以作为神经网络中的归纳偏差加以利用,而节点大小实际上使得这样的数据集不可能有一个完全连通的图。
图的位置编码
在NLP中,大多数情况下,基于Transformer的模型由每个字的位置编码补充。这对于确保每个单词的唯一表示以及甚至保留距离信息是至关重要的。
对于图,唯一节点位置的设计是具有挑战性的,因为存在防止规范节点位置信息的对称 。事实上,大多数GNN学习的是节点位置不变的structural node信息。
这就是为什么简单的基于注意力的模型,如GAT,其中attention是局部邻域连通性的函数,而不是全图连通性。
为了更好地对距离感知信息进行编码,(附近节点具有相似的位置特征,而较远的节点具有不同的位置特征)使用拉普拉斯特征向量作为图变换中的PE。
作者在训练过程中随机反转特征向量的符号,遵循 Benchmarking graph neural networks 的做法 。预先计算了数据集中所有图的拉普拉斯特征向量。通过对图的拉普拉斯矩阵进行因式分解来定义特征向量;
使用节点的k个最小特征向量作为其位置编码,并对节点 $i$用 $λ_i$表示。
Graph Transformer Architecture
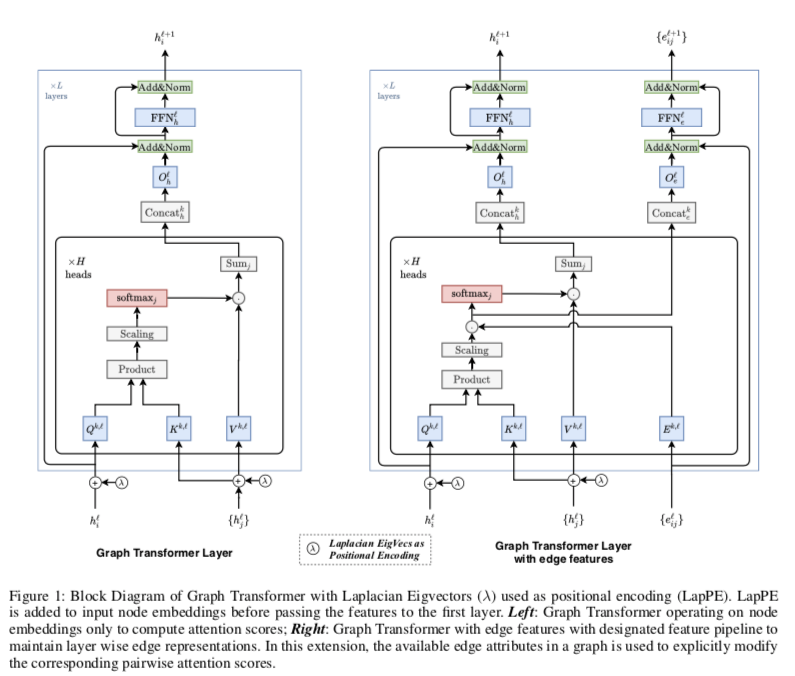
左边的模型是为没有明确边属性的图设计的,右边的模型维护一个指定的边特征,以结合可用的边信息并在每一层维护它们的抽象表示。
输入
图 $G$ 的节点特征 $\alphai \in R^{d_n \times 1}$ ,节点$i,j$ 对应的边特征$\beta{ij}\in R^{d_e \times 1}$
$\alphai, \beta{ij}$ 通过线性映射成为$d$ 维隐层特征 $hi^0 , e{ij}^0$ :
其中,$A^0\in R^{d\times d_n}, B^0\in R^{d\times d_e}, a,b\in R^d$
将位置编码线性映射后加入节点特征:
其中,$C^0\in R^{d\times k}, c^0 \in R^d$ . 请注意,拉普拉斯位置编码仅添加到输入层的节点特征,而不是在中间层。
Graph Transformer Layer
第 $l$ 层节点更新:
其中,$Q^{k,l}, K^{k,l}, V^{k,l} \in R^{d_k \times d}, O^{l}_h\in R^{d\times d}$ ,$k$ 注意力haed数。
为了数值稳定性,在取softmax 的输出被限制介于−5到+5之间。
然后,将attention输出$h^{l+1}$传递给FFN,然后是残差和归一化层,如下所示:
其中 $W_1^l\in R^{2d \times d}, W_2^l \in R^{d\times 2d}$ 为了说明清楚,省略了偏执项。
Graph Transformer Layer with edge features
旨在更好地利用图数据集中以边属性形式提供的丰富特征信息。
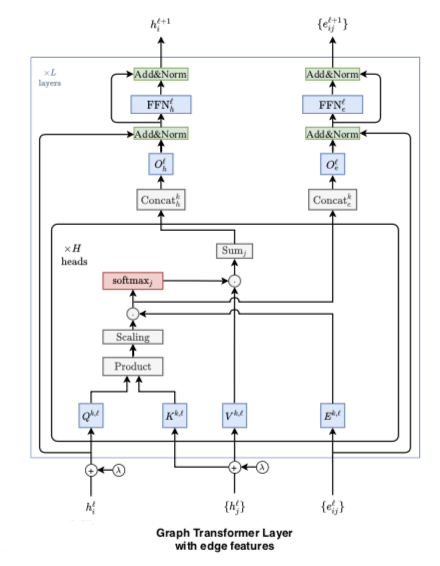
这些边特征是对应于节点对的相关分数,所以将这些可用的边特征与通过 pairwise attention计算的隐含边分数联系起来。换言之,假设在query 和 key 特征投影相乘之后,当节点 $i$ 关注节点 $j$ 时,计算在softmax注意分数 $\hat w{ij}$, 将该分数 $\hat w{ij}$ 视为关于边 $
利用边特征改进已经计算的隐式注意分数 $\hat w{ij}$ 。通过简单地将两个值 $\hat w{ij}$ 和 $e_{ij}$ 相乘来实现的
指定的节点对称的边特征表示管道,用于将边属性从一层传播到另一层:
其中 $Q^{k,l}, K^{k,l}, V^{k,l} ,E^{k,l} \in R^{d_k\times d} , O^l_h,O^l_e\in R^{d\times d}$
其余d 也是要经过Transformer架构中的其他成分。
实验
 wechat
wechat alipay
alipay





