Do Multi-Hop Question Answering Systems Know How to Answer the Single-Hop Sub-Questions?
Do Multi-Hop Question Answering Systems Know How to Answer the Single-Hop Sub-Questions?
这是一篇比较有意思的工作,但是出发点是多跳阅读理解的本质问题。
多跳QA需要一个模型来检索和整合来自多个段落的信息来回答问题,作者认为现有的评估标准,EM和F1并不能证明在多大程度上学会了多跳推理能力。
所以作者根据多跳QA中的桥接实体生成了一千个相关的子问题,来测试模型的能力,并期望这样能说明一些问题。
做法
当设计一个多跳问题时,我们要求模型去检索一系列句子作为证据,然后对他们进行推理来回答问题。作者设计了一个HotpotQA干扰项集,的子问题集,期望模型如果具有了多跳的推理能力,多跳的问题可以回答的话,那么单跳问题也可以回答。但是这个单跳问题不是凭空出现的和原问题不相关的问题。如下图所示:
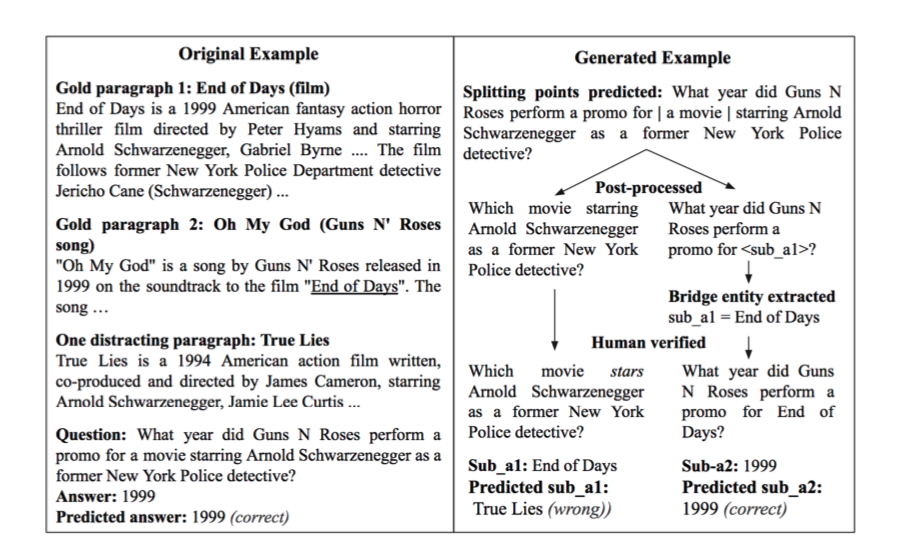
这是一个典型的桥接问题,问题是:罗斯为阿诺德·施瓦辛格饰演的前纽约警探主演的一部电影做宣传是在哪一年?
想要回答问题,我们就必须先知道施瓦辛格在哪个电影里扮演了纽约警探,也就是必须找到桥梁实体 Gold Para2 中的电影《End of Days》才能回答。
那么子问题的建立就很自然的可以分为,
1、施瓦辛格正在哪个电影里扮演了纽约警探?
2、罗斯在那一年为电影《End of Days》做了宣传?
第一个问题的答案正好是桥梁实体,第二个问题的答案是最终答案。
作者认为只有模型能够完整的回答这些问题,说明模型就具备了多跳推理能力。
生成方法是半自动的:
- 首先,我们通过预测断点将每个源问题分解成若干子串
- 其次,进行post processed,生成两个子问题。使用一些启发式方法从段落中提取子问题的答案。
- 最后,将生成的候选评价实例发送给人工验证。
实验
作者认为有些预测答案,虽然部分匹配EM=0但是语义上是正确的,也应该被算作预测正确。如下这种:

新的评估标准:给定黄金答案文本跨度 $a_g$ 和预测答案文本 $a_p$,如果满足以下两个要求之一,则它们部分匹配:
$f1$ 值大于0.8,直接认为符合要求, 或者,$f1$ 大于0.6 ,且标准答案文本跨度包含了预测文本的答案或预测答案包含了标准答案。
Baseline 选用开源的CogQA、DFGN、DecompRC
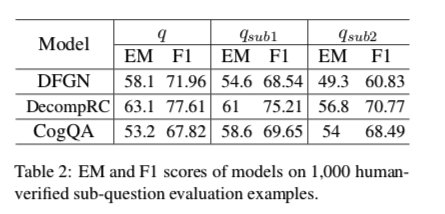
实验结果发现CogQA稍微好一些
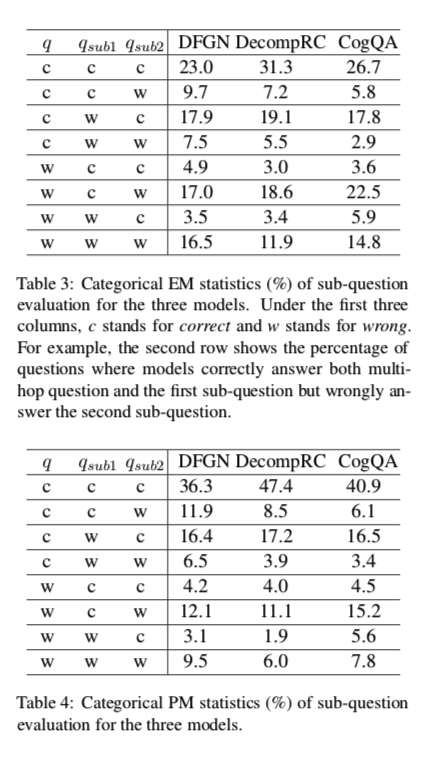
模型有很高的概率没有答对其中一个问题。
作者将这些示例称为模型故障案例:模型故障案例在所有正确回答的多跳问题中所占的百分比被定义为模型故障率。
CogQA PM下的故障率: $(6.1+16.5+3.4)/(40.9+6.1+16.5+3.4) \times100\% = 38.86\%$
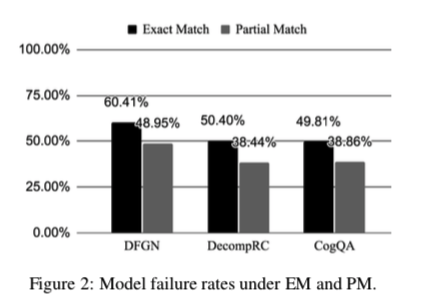
所评估的所有三个模型都有很高的模型失败率,这表明这些模型学会了回答复杂的问题,而没有探索推理过程的多个步骤。当使用EM和PM分数进行评估时,也会出现同样的现象。
After analyzing the model failure cases, we ob- serve a common phenomenon that there is a high similarity between the words in the second sub- question and the words near the answer in the con- text. The model has learned to answer multi-hop question by local pattern matching, instead of going through the multiple reasoning steps. For the ex- ample presented in Figure 1, the model may locate the answer “1999” for the multi-hop question by matching the surrounding words “ Guns N Roses” in the second sub-question. Despite answering the multi-hop question correctly, the model fails to identify the answer of the first sub-question which it is expected to retrieve as a multi-hop QA system.
 wechat
wechat alipay
alipay





