Dynamically Fused Graph Network for Multi-hop Reasoning
Dynamically Fused Graph Network for Multi-hop Reasoning
受人类分步推理行为的启发,提出了动态融合图网络(DFGN),回答那些需要多个分散证据并在这些证据上进行推理的问题。不依赖于任何额外的预定义知识基础,能回答开放领域中的问题。
大体过程
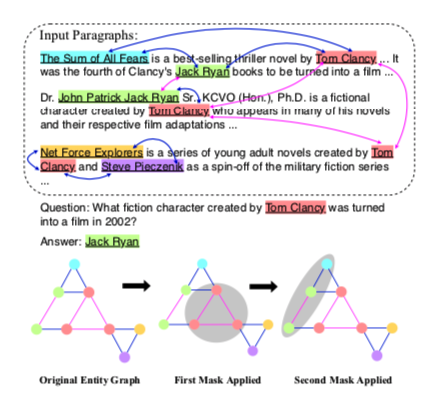
给出了一个问题和三个段落。DFGN通过从多个段落构造实体图,预测动态掩码选择子图,沿着图传播信息,最后将图中的信息传回文本来定位答案,从而对事实进行多步推理。节点是实体引用,带颜色节点表示潜在实体。边由共现关系构造而成,每一步都由DFGN选择灰色圆圈内的子图来处理。
挑战
- 由于并不是每个文档都包含相关信息,基于多跳文本的问答需要从多个段落中滤除噪声并提取有用信息。
作者思路: 通过DFGN这种多轮迭代的动态实体图来解决,如上图DFGN每一轮都通过掩码预测模块在动态图上生成和推理,其中不相关的实体被屏蔽,只有推理远被保留也就是灰色圆圈内的子图,这种做法缓解了误差的传播问题。
此外,DFGN的预测mask的过程可隐含地导出推理链,可以解释推理结果。针对开放域语料库基本真值推理链难以定义和标注的问题,提出了一种可行的弱监督掩码学习方法。提出了一种新的度量来评估预测推理链和构建的实体图的质量。
但这样做有用的信息被mask了怎么办?怎么确定的mask范围?其实是用了注意力机制计算实体的权重,后文写。
- 不能直接从实体图中提取出答案,现实中,答案可能不在所提取的实体图的实体中。
作者思路:在DFGN中设计了一个fusion处理模块,不仅将信息从文档聚合到实体图(Doc2graph),还将实体图的信息传播回文档表示(Raph2doc)。通过文档token和实体在每一跳迭代地执行融合过程,然后从文档令牌获得最终结果答案。Doc2graph和Graph2doc的融合过程以及动态实体图共同改善了文档信息和实体图之间的交互性,从而减少了噪声,从而提高了答案的准确性。
相当于在tokens的表达中加入了推理图中的推理信息,这个思想还是挺不错的。
具体过程
模仿人类对QA的推理过程。从查询感兴趣的实体开始,聚焦于开始实体周围的单词,连接到在邻居中发现的或由相同表面信息链接的某些相关实体,重复该步骤以形成推理链,并且落在可能是答案的某个实体或片段上。
DFGN包含五个组件:
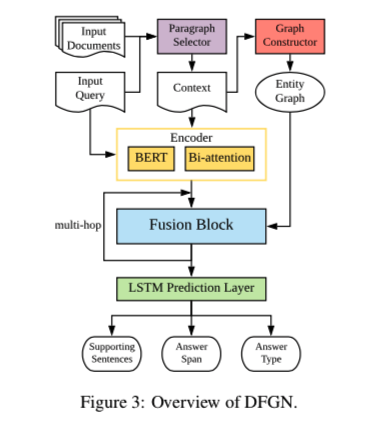
- 段落选择子网络
- 实体图构建模块
- 编码层
- 用于多跳推理的融合模块
- 最终预测层
Fusion Block
这里只着重写一下Fusion Block
在为查询Q和上下文C计算嵌入后,剩下的挑战是如何识别支持实体和潜在答案的文本跨度。
Fusion Block从 $Q_0$和 $C_0$ 开始,寻找一步支持实体。
- 通过计算实体嵌入从tokens将信息传递到实体(Doc2Graph Flow)
- 在实体图上进行信息传递
- 传递信息从实体图到文本tokens(Graph2Doc flow)
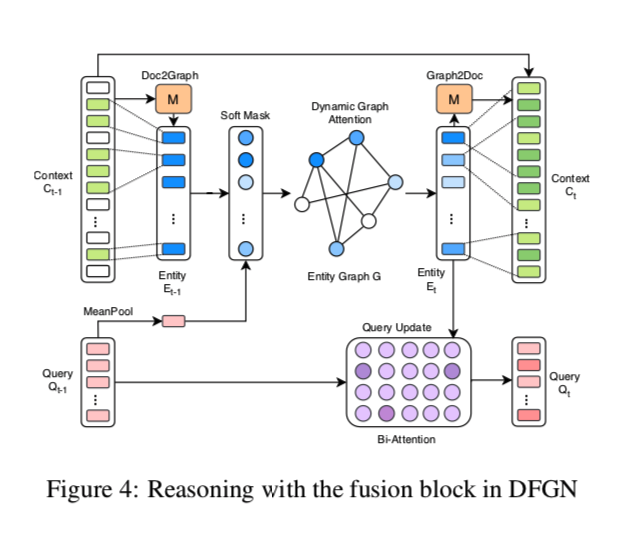
Doc2Graph Flow
由于通过NER工具识别每个实体,因此利用与实体相关联的文本跨度来计算实体嵌入(Doc2Graph)。
为此,作者定义了一个 M 是01矩阵,$M{i,j}$ 的值意思是,如果第 $i$ 个token在第j个实体的范围内,则 $M{i,j}=1$
这个 M 用于选择与实体相关联的文本范围。这其实是一个池化操作,将上下文C 的嵌入变成了实体E的嵌入 。
$E{t-1} = [e{t-1,1},…,e_{t-1,N}] \in R^{2d_2\times N}$ 这个模块作者定位 Tok2Ent,就是上图的左边部分。
Dynamic Graph Attention
然后是图中的中间部分,动态图注意力部分。
在从输入上下文Ct−1获得实体嵌入后,我们应用图神经网络将节点信息传播给它们的邻居。我们提出了一种动态图注意机制来模仿人类的循序渐进的探索和推理行为。与q越相关,邻居节点从附近接收的信息越多。
首先通过在实体上创建 Soft Mask 来识别与查询相关的节点。它充当信息看门人,即只允许与查询有关的那些实体节点传播信息。
使用查询嵌入和实体嵌入之间的注意力网络来预测 Soft Mask $m_t$,其目的是表示第 t 个推理步骤中的开始实体:
其实就是用注意力机制计算每个实体嵌入的权重。$V_t$ 是线性映射矩阵。
总之就是通过Soft Mask,得到想要的开始推理的实体,并将它送入图中初始化。噪声信息不放入图中,相当于过滤掉。
此外,作者引入一个弱监督信号来诱导每个 Fusion Block 处的软掩码来匹配启发式掩码。对于每个训练案例,启发式掩码包含从查询中检测到的开始掩码,并且通过对相邻矩阵应用广度优先搜索(BFS)获得的附加BFS掩码给出开始掩码。然后,将预测的软掩码和启发式之间的二进制交叉熵损失添加到目标。(跳过那些无法从查询中检测到起始掩码的情况)。
在送入图后的信息聚合方式是使用的GAT,但有一点作者和以前的GAT不同,
在Dynamic Graph Attention中,每个节点隐层的列进行求和,形成一个新的实体状态,其中包含它从邻居收到的全部信息:
其中 $B_i$ 是邻居实体集合中的第 i 个实体,所以一次更新后的实体表达为 $E^{(t)} =[e_1^{(t)},…,e_N^{(t)}] $
Updating Query
一条推理链包含多个步骤,每一步新访问的实体就是下一步的起始实体。
为了预测下一步期望的起始实体,引入了一种Updating Query机制,通过当前步骤的实体嵌入来更新查询嵌入。
Graph to Document Flow
利用Tok2Ent和动态图关注度,实现了实体级的推理步骤。然而,不受限制的答案仍然无法追溯。
为了解决这个问题,开发了一个Graph2Doc模块来保持信息从实体回流到上下文中的tokens。因此,与答案有关的文本跨度可以在上下文中本地化。
使用Doc2Graph Flow中一样的M矩阵,将$C_{t-1}$ 中的先前tokens嵌入和 对应于该令牌的关联实体嵌入对应回来。
M中的每一行对应一个令牌,因此如果该令牌出现在实体的提及中,就使用它从 $E_t$ 中选择一个实体的嵌入。利用LSTM层进一步处理该信息,以产生下一级上下文表示: $C^{(t)} = LSTM([C^{(t-1)}, ME^{(t)T}])$
Prediction
有四个输出维度,1.支持句,2.答案的开始位置,3.答案的结束位置,4.答案的类型。
使用四个同构的LSTM $F_i$ 是逐层堆叠的。最后Fusion Block的上下文表示被发送到第一个LSTM $F_0$。每个$F_i$输出的logits为$ O∈R^{m×d2}$ ,并计算这些logit上的交叉熵损失。
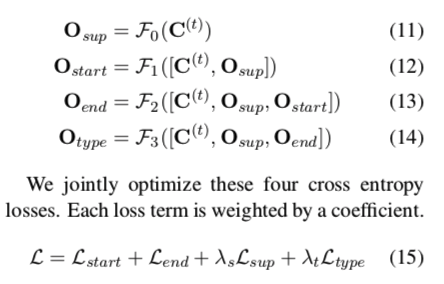
实验
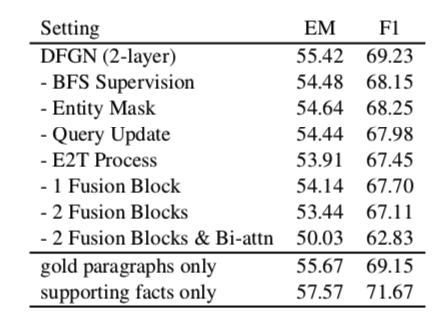
作者提出的推理链质量的衡量标准
ESP(实体级支持)分数
推理链是实体图上的一条有向路径,因此高质量的实体图是良好推理的基础。由于NER模型的精度有限和图结构的不完备性,31.3%的发展集中的情况不能进行完整的推理过程,其中至少有一个支持语句不能通过实体图到达,即在这个句子中没有实体被NER模型识别。我们将这类情况命名为“缺失支撑实体”,这种情况的比率可以用来评价图的构造质量。
下面,在给出ESP(实体级支持)分数之前,我们首先给出几个定义。
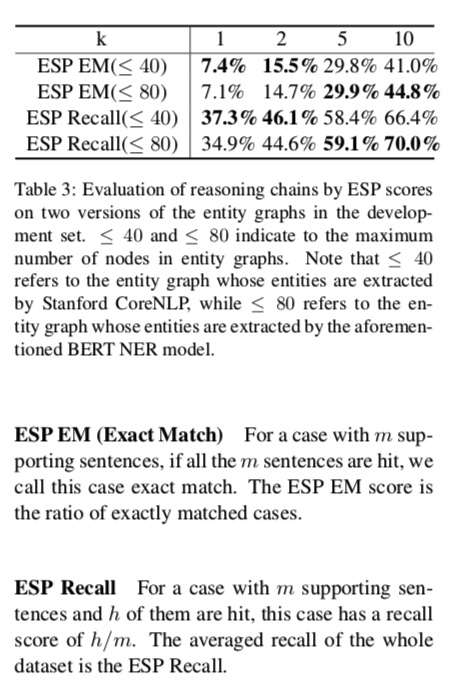
案例分析

 wechat
wechat alipay
alipay





