Hierarchical Graph Network for Multi-hop Question Answering
Hierarchical Graph Network for Multi-hop Question Answering
https://arxiv.org/pdf/1911.03631.pdf
这篇文章也是HotpotQA数据集上的关于解决多跳问答场景的,在干扰项排行榜和全维基排行榜都曾是前列。
多跳QA和HotpotQA数据集 : HotpotQA数据集:A Dataset for Diverse, Explainable Multi-hop Question Answering
其特点是
- 通过在问题、段落、句子、实体等不同粒度上构建层次图(HGN)
- 通过HGN这种节点粒度层次可以区分,进一步进行多任务推理:段落选择、支持句预测、实体抽取、最终答案预测
如何构图
首先来介绍下作者是如何构图的。
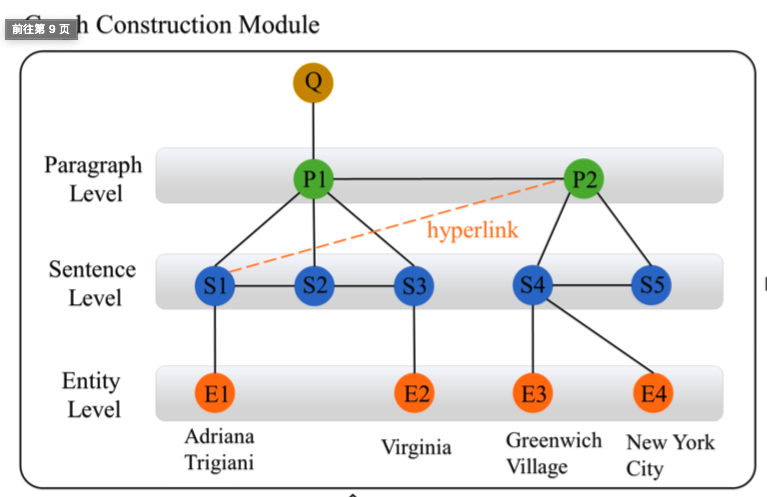
段落由句子组成,每个句子包含多个实体。这个图自然是以层次结构编码的,它也激发了作者构建层次图的动机。
四种节点类型:
- 问题节点Q
- 实体节点E
- 段落节点P:对于每个段落节点,在段落中的所有句子之间添加边。
- 句子节点S:对于每个句子节点,提取句子中的所有实体,并在段落句子节点和这些实体节点之间添加边。
七种边类型:
- 问题节点和定位段落节点有边
- 问题节点和问题中的实体节点有边
- 段落节点和段落中的句子节点有边
- 句子节点与其链接的段落节点之间的边(超链接链接)
- 句子节点和句子中所提取的实体节点有边
- 段落和段落之间有边(论文是取和问题最相关的前两个段落)
- 存在同一个段落的句子节点
挑战与动机
HotpotQA的方案一般是先用一个检索器去找到包含正确答案的段落。然后在用MRC模型去选择段落去预测答案。
目前的挑战:即使通过多个段落成功地确认了推理链,如何从分散的段落中收集不同粒度级别的证据共同回答并支持事实预测,仍然是一个关键的挑战。
作者认为多跳阅读推理直观的步骤:
- 找到与问题相关的段落
- 在段落中选择强有力的证据
- 从获得的证据中查明正确答案
作者也是这么实现的,并创新的采用了多个层级的粒度信息去构图推理。
HGN
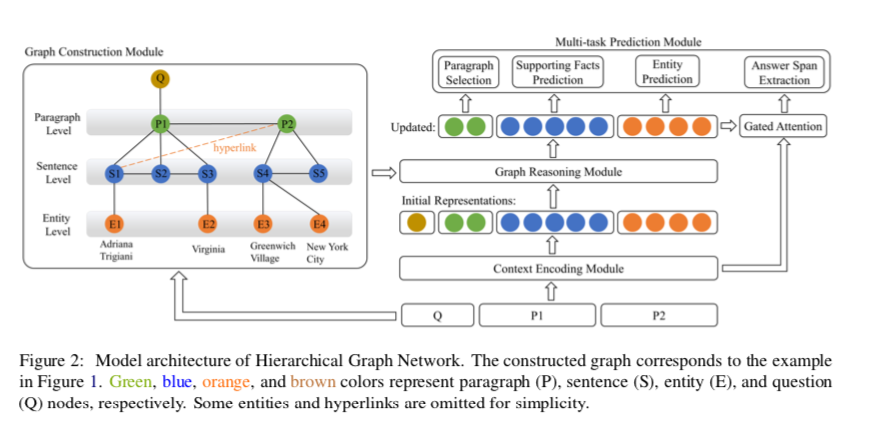
模型包含四个模块:图构造模块、上下文编码模块、图推理模块、多任务预测模块
图构造模块
就是构造上文的七种边四种节点,形成层级图
一共要考虑两步:
选择相关段落:
第一跳:用预训练模型加一个二分类判断段落中是否包含支撑事实,
如果返回多个段落则选择排名靠前的两个作为段落节点。
如果标题匹配没有结果,则进一步搜索段落中包含问题实体的。
如果还是搜索失败,将会从段落排序中选择排名最高的段落。
确定第一跳后:下一步就是段落中找到可以通向其他相关段落的事实和实体(不再依赖实体链接,这可能会很引入噪音,而是在第一跳段落中使用超链接来发现第二跳段落。)
- 添加表示所选段落内的句子/实体之间的连接的边。
上下文编码模块
给出构建的层次图,下一步是获得所有图节点的初始表示。首先将所有选定的段落合并到上下文C中,将其与问题Q连接起来,输入Roberta。
$C = {c0,c_1,…,c{n-1}} \in \text{R}^{n\times d } , Q ={q0,q_1,…,q{m-1}}\in \text{R}^{m\times d}$
问题Q随后是一个双向注意力层。(2017. Bidirectional attention flow for machine comprehension. ICLR.)
在上下文表示C之上用BiLSTM,并且从BILSTM的输出中提取不同节点的表示,表示为$M∈R^{n×2d}$。
在BiLSTM后通过预测开始和结束位置来得到句子和实体节点。
$p_i$ 第i段落节点、$s_i$ 第i句子节点、 $e_i$ 第i个实体节点、q 问题节点 $\in \text{R}^d$
图推理模块
获得层次图所需要的节点:
- 段落节点:$P = {pi}^{n_p}{i=1} , n_p=4$
- 句子节点:$S = {si}^{n_s}{i=1}, n_s=40$
- 实体节点:$E = {ei}^{n_e}{i=1}, n_e=60$
定义图的临界矩阵为$H = {q,P,S,E} \in \text{R}^{g\times d } , g= n_p+n_s+n_e+1$
经过GAT后,得到更新过后的每个节点表示$P’,S’,E’,q’$
为了让图信息进一步提取上下文答案跨度,这里还用更新后的节点表示H‘和之前的上下文表示M,通过一个门控注意力机制,用于答案跨度的预测。
具体表示为:
其中:$W_m \in \text{R}^{2d\times 2d}$ ,$W’_m \in \text{R}^{2d\times 2d}$ ,$W_s \in \text{R}^{4d\times 4d}$ , $W_t\in \text{R}^{4d\times 4d}$
多任务预测模块
- 基于段落节点的段落选择
- 基于句子节点的支撑事实预测
- 基于实体节点和上下文G表示的答案预测
最终目标函数
其中$\lambda_{1,2,3,4}$ 超参数权重
$L_{type}$ 是预测答案类型的损失
错误分析
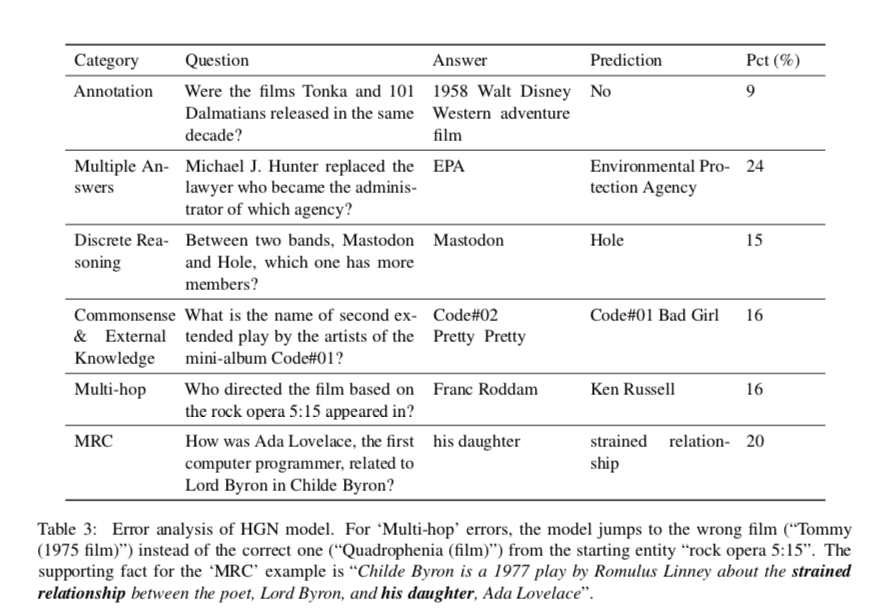
作者在这分析了模型的弱点(为将来的工作提供了见解),在dev集中随机抽样了100个答案f1为0的示例。
作者总结了六类错误
Annotation批注:数据集中提供的批注不正确
上图第一行:“Tonka”和“101只斑点狗”是在同一个十年上映的吗?数据集给的答案和实际情况不一样?这种应该是数据集错误吧, 这种错误占了9%。这种问题应该不是模型的弱点吧?
Multiple-Answers:问题可能有多个正确答案,但数据集中只提供一个答案
迈克尔·J·亨特取代了成为哪家机构管理员的律师?答案EPA是预测答案的缩写,这种问题也比较难解决,占了24%是比重最多的。
Discrete Reasoning: 这种类型的错误经常出现在“比较”题中,需要离散推理才能正确回答问题; 16%
在Mastodon和Hole这两个乐队中,哪个成员更多? 可能是已知这两个乐队人数,要比较这两个数的大小
Commonsense & External Knowledge: 要回答这类问题,需要常识或外部知识
迷你专辑Code#01的艺人第二次延长演出的名字是什么?
Multi-hop:模型不能进行多跳推理,从错误的段落中找到最终答案 16%
这部根据5:15出现的摇滚歌剧改编的电影是谁导演的?
MRC: 模型正确地找到了支持段落和句子,但预测了错误的答案跨度。 20%
艾达·洛夫莱斯,第一位计算机程序员,在“恰尔德·拜伦”中与拜伦勋爵有什么关系?答案是他的女儿,模型回答成紧张的关系,说明模型没有完全理解问题中的关系。
可以看出HGN对于阅读理解的进行鲁棒性的回答还是有所不足,面对相同答案的多样性还有进一步的改进空间。
对于句子理解和推理定位还不够特别准确。
 wechat
wechat alipay
alipay





