Select, Answer and Explain-Interpretable Multi-hop Reading Comprehension over Multiple Documents
Select, Answer and Explain: Interpretable Multi-hop Reading Comprehension over Multiple Documents
摘要
选择、回答和解释(SAE)系统解决多文档RC问题。
首先主要创新,用文档分类器过滤掉与答案无关的文档,从而减少分散注意力的信息量。
然后将所选择的答案相关文档输入到模型以联合预测答案和支持句子。
该模型在答案预测的表征层和支持句子预测的句子层都设置了多任务学习目标,
并在这两个任务之间进行了基于注意力的交互,对模型进行了优化。
关键词:过滤无关文档、多任务学习、混合注意力交互
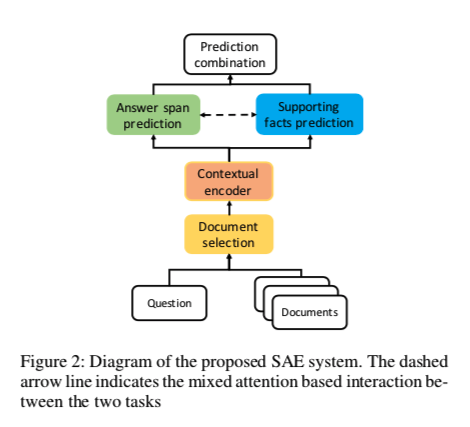
在HotpotQA中什么是gold doc
HotpotQA通过为答案提供支持句来鼓励可解释的QA模型,这些支持句通常来自多个文档,如果文档包含答案或包含对答案的支持句,则称为“黄金文档”。
应答文本,它可以是一段文本或“是/否”。
作者从答案和支持句标签导出GOLD文档标签。我们使用 $D_i$ 表示文档 i:如果Di是黄金文档,则标记为1,否则标记为0。还将答案类型标记为以下注释之一:“Span”、“Yes”和“No”。
选择gold doc(过滤文档)
答案预测和支持句预测的上游任务。将分类排名最靠前的文档作为预测的黄金文档 gold doc。
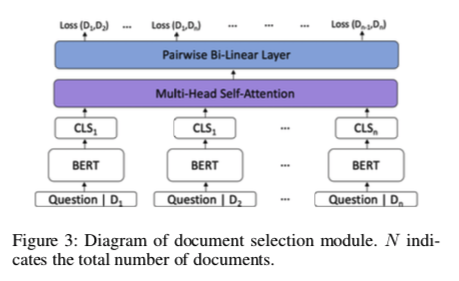
做文档过滤最直接做法就是采用bert的CLS摘要向量,做交叉熵分类
$t_i$ 是 $D_i$ 的标签,n是文档数,$P(D_i)$ 是文档i在标签 $t_i$ 中的概率。
这种简单的方法的缺点:单独处理每个文档,而不考虑下游多跳推理任务所必需的文档间交互和关系。
为解决此问题,作者提出了一个新的模型,如图上图CLS后,加了一层多头注意力层。
意在:增加对从不同文档生成的“CLS”标记的关注的动机是鼓励文档间的交互。文档间交互对于文档间的多跳推理至关重要。
优化:采用了新的成对学习排序损失。还将问题从分类问题描述为两两学习排序问题,
通过将文档与所有其他文档进行比较,该模型能够更好地将一小部分黄金文档与睡觉分散注意力的文档区分开来。
给每个文档一共分数 $S(.)$
如果 $D_i$ 是gold doc $S(D_i) = 1 $, 否则 $S(D_i) = 0$
然后,标记每对输入文档:给定一对输入文档 $(D_i,D_j)$,标签 $l$设置为:
还认为包含答案范围的文档对于下游任务更重要。因此,如果$D_i$是包含答案跨度的黄金文献,$S(D_i)=2$。
再将MHSA输出传递给双线性层来输出每对文档的概率,双线性层基于二元交叉熵进行训练,如下所示:
相关性定义为$ R_i=\sum_j^n(P(D_i,D_j)>0.5)$。将来自该相关性排序的前k个排序的文档作为的过滤文档。
答案和解释
模型采用多任务学习的方式进行训练,以联合预测答案和对黄金文档的支持意义。
基于GNN构建多跳推理图,将上下文语句嵌入作为节点,而不是像以往的工作那样以实体作为节点,直接输出带有答案预测的支持语句。
为什么不用NER因为作者认为:
目前GNN在QA任务中的应用通常需要实体作为图形节点,并且通过在具有上下文信息的节点上进行消息传递来实现推理。这仅在预定义的一组目标实体可用时才有可能。否则,需要使用命名实体识别(NER)工具来提取实体,这可能会导致图推理中的冗余实体和噪声实体。如果答案不是命名实体,则需要进一步处理以定位最终答案。
token-level and sentence-level 多任务学习
基于一种新的混合注意池机制
将GNN中使用的上下文语句嵌入归结到令牌表示上。注意力权重是根据令牌表示上的答案广度日志和自我注意输出来计算的。这种基于注意力的交互能够利用“回答”和“解释”任务之间的互补信息。
答案预测
针对bert输出的每一个$H_i$ 用两层MLP做答案起始位置预测 $L$ 为长度
其中$\hat Y$的第一行是起始位置的逻辑,第二行是结束位置的逻辑。$y^{star}t$和 $y^{end}$ 是范围 [0,L-1] 中的开始位置和结束位置的标签。CE表示交叉熵损失函数。
支持句预测
预测输入上下文中的句子是否为答案预测的支持证据。为了实现句子级预测,我们首先获得$H_i$中每个句子的序列表示。$H_i$ 是bert的token输出。
$S^j$是表示语句 j 内的标记嵌入的矩阵( 这里省略了样本索引i)。 $j^s$ 和 $j^e$ 定义了开始和结束位置,$L_j$ 是语句$j$ 的长度。
多任务
答案预测任务和支持句预测任务可以相辅相成。
据观察,答案预测任务总是可以帮助支持句子预测任务,因为有答案的句子总是一条证据;
但反过来情况不是一样的,因为可能有多个支持句子,概率最高的句子可能不包含答案
所以答案预测任务总 可以帮助支持句子预测任务,因为有答案的句子总是一个证据;
反之亦然,因为可能有多个支持句子,概率最高的句子可能不包含答案。
因此,为了揭示这两个互补任务之间的相互作用,提出了一种基于注意力的总结句子表示法,以引入来自回答预测的互补信息。
注意力权重的计算方法如下:在Sj上用自我注意计算一部分注意力,另一部分来自答案预测任务的起始位置日志和结束位置日志的总和。
Sj是表示语句j 的标记嵌入的矩阵
$f_{att}$ 是一个两层MLP输出size为1,$\sigma$是softmax
$α_j ∈ R^{L^j×1}$表示句子j的每个token上的关注度权重。
构建GNN
接下来,在语句嵌入Sj上建立GNN模型,以显式地促进对预测gold doc中所有语句的多跳推理,从而更好地利用复杂的关系信息。使用语句嵌入Sj来初始化图的节点特征。采用基于多关系图卷积网络(GCN)的消息传递策略来更新图的节点特征,并将最终的节点特征输入到MLP中,得到每个句子的分类。
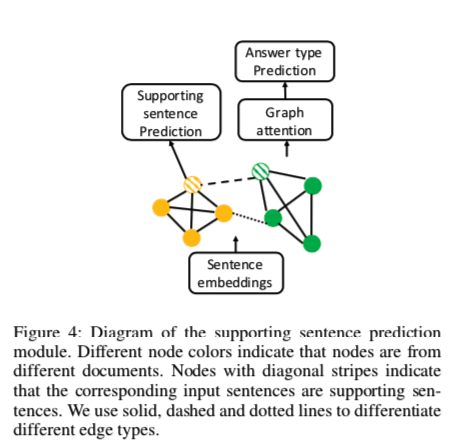
根据问题和句子中出现的命名实体和名词短语设计了三种类型的边:
- 如果两个节点最初来自同一文档,则在这两个节点之间添加一条边(上图中的实节点)
- 如果表示两个节点的句子在问题中都具有命名实体或名词短语(可以是不同的),则在来自不同文档的两个节点之间添加边。(图中的虚线)
- 如果表示两个节点的句子具有相同的命名实体或名词短语,则在来自不同文档的两个节点之间添加一条边。(图中的虚线)
第一种类型的边的动机是希望GNN掌握每个文档中呈现的全局信息。
第二类和第三类边,为了以更好地捕捉这种跨文档推理路径。跨文档推理是通过从问题中的实体跳到未知的桥梁实体或比较问题中两个实体的属性来实现的 。
对于消息传递,使用具有门控机制的多关系GCN。
假设 $h^0_j$ 表示从语句嵌入 $S_j$的初始节点嵌入,则一跳(或一层)之后的节点嵌入计算可表示为:
其中R 是一些列边类型, $N^r_j$ 是边类型为r的 j 节点的邻居。
$h^k_n$ 是节点n的第k层节点表示。
$f_r、f_s、f_g$中的每一个都定义了输入节点表示上的变换,并且可以使用MLP来实现。
门控$g_j^k$ 是由0和1之间的值组成的向量,用于控制来自计算的更新$u^k_j$ 或来自原始节点表示的信息。
函数$act$表示非线性激活函数。
最后得到每个节点的最终表示 $h_j$ 后用两层MLP 最终预测 。
$\hat y^{sp}j = sigmoid(f{sp}(h_j))$
除了支持句子预测任务之外,还在GNN输出之上添加了另一个任务,以说明“Yes/No”类型的问题。
预测任务描述为3类(“Yes”、“No”和“span”)分类
引入:
$h = \sum_j a_jh_j$
$a = \sigma(\hat y^{sp})$
$\hat y^{ans} = f_{ans}(h)$
最终loss表达为:
$BCE()$ 二元交叉熵函数
为了考虑不同损失的尺度差异,在跨度损失中加入了一个权重γ。
 wechat
wechat alipay
alipay





