HopRetriever:Retrieve Hops over Wikipedia to Answer Complex Questions(AAAI2020)
HopRetriever:Retrieve Hops over Wikipedia to Answer Complex Questions(AAAI2020)
https://arxiv.org/abs/2012.15534
摘要
- 大型文本语料库中收集支持证据对于开放领域问答(QA)是一个巨大的挑战。
- 本文方法:
- 将hop定义为超链接和出站链接文档的组合
- 超链接编码成提及嵌入,相当于在上下文被提及的结构知识,表示出站链接实体建模。
- 出站链接文档编码成文档嵌入,相当于非结构化的知识。
- 使用Hotpot数据集,该数据集文章我在这里写过[TODO]
me:想要更好的检索,光用匹配一种检索方式不好,可以结合相关语义信息同时进行检索,会更准确。
那么难点就是如何找到相关部分提取语义信息用于检索。
介绍
多跳问答任务需要从多个支持文档中搜集分散的证据,来提取答案。最近主流方法是将多跳证据收集视为迭代文档检索问题。
在开放域下,多跳QA的一个关键部分是从整个知识源中检索证据路径,分解成几个单步文档检索。
另一part是在基于知识库KB下,并尝试像虚拟结构化知识库(KB)那样遍历文本数据,专注于提到的实体。
如这篇文章关于认知图谱的[TODO]我也写过。
作者认为,线索收集可以分为两种
- 实体介绍性文档内的信息丰富非结构的事实,关注非结构实体知识。
- 实体本身之间的结构化和隐式关系,关注结构化实体知识。
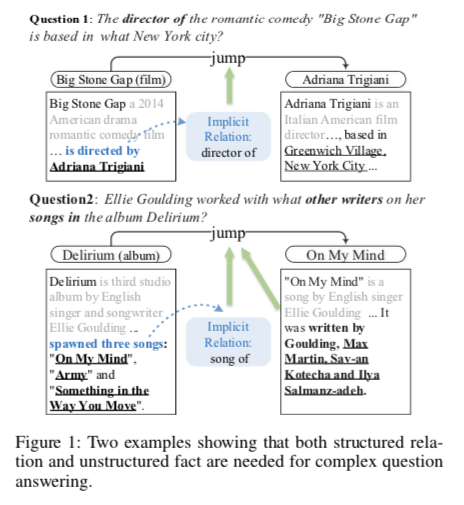
结构性知识是指提及关系。可能是对应的Q1从一篇文章中提及的。Q1的左边好像是文章
非结构性知识是指知识库之类外来知识。可能是对应Q2从知识库得来。Q2的左边好像是个知识库
回答一个复杂的问题需要结合上面两种知识,我觉得对啊,就像问人一个问题,我已有的知识可能不够,我通过搜索引擎搜到一些知识来补充我回答这个问题的能力。
本文作者要考虑的问题是,基于什么证据可以跳到第二个文档进行进一步检索。
Q1是基于文档匹配”directed by”来找到下一个跳,从而可以有充足的证据。
Q2问题更复杂一点,有三首歌被提及,只有其中一首是相关问题的,像上面那种关系不足以去在三者中做选择。这就需要通过和实体相关的无结构知识才能找到答案。
出发点
所以作者认为,为了在Wikipedia中收集足够的支持证据,有必要同时考虑实体之间的关系结构和隐藏在介绍性文档中的非结构化知识。
当应答过程遵循“顺藤摸瓜”的模式时,隐含的实体层次关系使得检索更加高效。但是,当关系链失败时,文档中的那些非结构化事实就会登台。
本文研究如何将结构化知识和非结构化知识结合起来,共同为证据收集做出贡献。
定义hop
定义hop为超链接和相应出站链接文档的组合,后面要将两种embedding结合为hop。
维基百科中的超链接暗示一个实体的介绍性文档如何提及其他一些内容
而出站链接文档存储所有非结构化的事实和事件,这使得一跳包含关系证据和拟事实证据,以供将来检索。
HopRetriever思路
对于维基百科文档中提到的每个实体,我们将其周围的文本上下文编码到提及嵌入中,以表示隐含的结构化知识。
对于文档中非结构化知识的表示,与以往的工作一样,使用BERT对文档文本进行编码,条件是原始问题。
对于每个步骤检索,从一个文档(实体)到另一个文档(实体)的跳跃可以从两个角度收集证据:
当前文档是如何提到另一个文档。
在另一实体的介绍性文件中隐藏了哪些事实
相关工作
文档级推理
这种方法在不知道先前检索到的证据文档的情况下独立地查找证据文档,当证据文档中的一个与原始问题有少量语义关系时,可能会导致检索失败。
为避免这个问题有些人提出引入多步检索器,实现对多个证据文件的重复检索。
最近2020年一个PathRetriver,是沿着文本图的出站链接检索文档路径的。利用文档的图结构,减少了每一步检索过程中文档的搜索空间,这比以往的迭代检索器要小得多。(这个可以看看是不是用图网络来对出站非结构关系知识进行学习的)
HopRetriever和他的最大不同是多考虑了,在文章之间的结构化和多值关系。
以实体为中心的推理
大多数QA都是以实体为中心进行推理的。通过实体提及来收集证据。
代表一个是认知图谱那篇,一个是Differentiable Reasoning over a Virtual Knowledge Base(ICLR 2020,)(这个可以安排读一读)
作者认为他们的问题是,当问题不是“顺藤摸瓜”时,提及本身不能为跳过哪个实体提供足够的推理证据。
我感觉不太认可,认知图谱那篇同样是用bert来提取下一跳hop,可以是相同语境下的一些线索啊,不是一定提及本身啊。可能bert学的没那么强大?
对问题分解
建议将一个复杂的问题分解为几个更简单的子问题,并在每个步骤进行单跳QA。
问题分解的挑战是确保每个子问题收集真正必要的证据。
如果结构化关系建立失败,可能不会建立出一个可推理的子问题,用于进一步跳跃。
方法细节
这块公式参数细节比较多,一点一点梳理。
任务定义
开放域的多跳问答一般分为两个模型:
- 检索模型 $D_q=Retriever(q,K)$ : 用来从大范围知识源K中收集很多证据。$D_q$ 应包含回答多跳问题所需的多个文档。
- 阅读模型 $a=Reader(q,D_q)$ : 将$D_q$和q中的所有文本事实连接在一起,并馈送到答案提取模型阅读器中,以获得答案a
每个维基百科页面对应一个实体 $ei$
附有介绍性的文档尾 $d_i$ ,如果在$D_i$中存在链接到$e_j$的锚点。就定义一个提及关系 $m{i,j} = e_i \rightharpoonup^{d_i} e_j$ 。
知识源的定义为$K={D,E,M}$
M 是 提及关系$m_{i,j}$的集合
E 是 实体$e_i$的集合
D 是 附加文档$d_i$的集合
论文的任务只是检索模型,且$D_q$ 是迭代得到的。在每个检索步骤,通过不仅检查包含在中的非结构化事实,而且还检查在最新选择的文档中对其的提及来获取文档。为了实现这一点,将非结构化的文本事实和提及分别编码,然后在一跳内将它们一起表示。当通过维基百科进行检索时,HopRetriever使用跃点hop作为匹配对象。
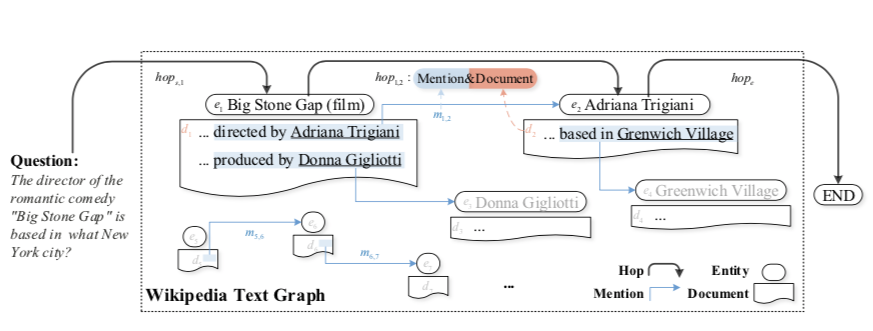
Hop 如何Embedding
Mention Embedding提及嵌入(结构化实体关系)
就是把包含entity的文档fed给bert,并且添加两个[MARKER] tokens选第一个被marker的作为mention embeding。
如果文中没有直接提到entity,就用一个可学习的向量$m_p$表示
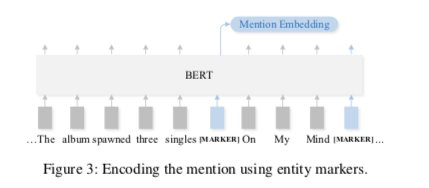
Document Embedding
将$d_j$中的文本事实(与q拼接)送入BERT,将关于实体$e_j$的非结构化知识编码为文档嵌入$u_j$,并将[cls]的输出表示作为文档嵌入向量:
Knowledge fusion
总体过程为,h为检索的历史向量。
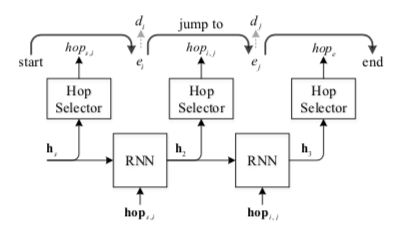
在第t步选择的$d_j$ 的概率计算为
细粒度句子级检索
一个文档不可能所有的句子都是答案所必须的,指出必须的那些支持句子,对于明确推理线索是必须的。
计算一个句子是不是留下采用以下公式:
大于0.5定义为支持句。
目标函数
序列预测模型就是上面的RNN图,在t步下的目标函数为
辅助支持句的预测任务,在第t步目标函数为
实验
数据集采用 HotpotQA [我要写TODO] 0564 个问答对。主要关注 fullwiki 部分。支持文档分散在 5M 的维基百科中。
实验包括三个部分:
- 初步检索。基于 TF-IDF 选取前 500 个文档,作为初始文档。
- 支持文档检索和支持句子预测。迭代检索初始文档。
- 答案提取。通过 BERT 获取答案。
作者还采用了一种基于 BERT 的神经排序器,获取更精确的前 500 个文档。同时,使用 ELECTRA (ELECTRA: Pre-training Text Encoders as Discrimi- nators Rather Than Generators. In International Conference on Learning Representations.)代替 BERT 进行答案获取。结果作为 HopRetriever-plus。这也体现了更好的初步检索的重要性。
不同类型问题的embedding权重,结构和非结构
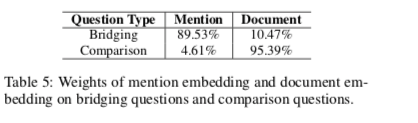
不同case的权重
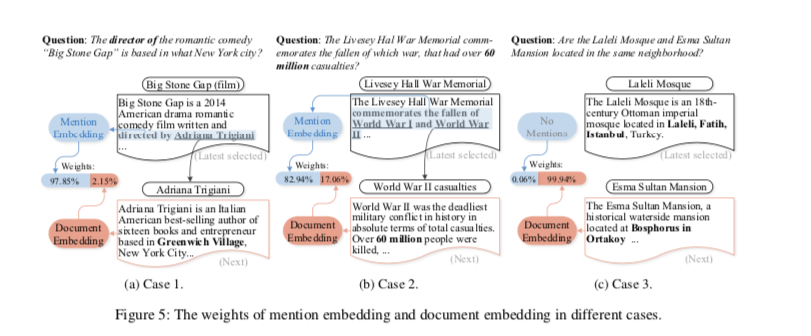
case3 当没有提及时,非结构化的文档embedding发挥主要作用
结论
HopRetriever 能够将结构性知识和非结构性知识进行结合,确定比较好的跃点hop。同时,跃点迭代模型能够一步步寻找下一个跃点,最终确定答案实体。除此之外,初步文档检索也是十分重要的内容,文章采用的神经排序器效果不错,值得后面继续研究。
参考文献
HopRetriever: Retrieve Hops over Wikipedia to Answer Complex Questions 论文阅读笔记)
 wechat
wechat alipay
alipay





